
As forensic examiners, we often have to analyze emails in isolation without the benefit of server metadata, neighbor messages, or data from other sources such as workstations. When authenticating an email in isolation, every detail counts—we review a long list of data points such as formatting discrepancies within the message body, dates hidden in MIME boundary delimiters, and header fields.
One data point I often see being overlooked is the Content-Length header field. The value this field contains can be leveraged for a simple but powerful check to verify an email’s payload. In this post, I will discuss how we need to preserve emails to be able to utilize the Content-Length header field, how to utilize the data in this field, and a couple of use case scenarios. Let’s start by defining Content-Length.
What Is Content-Length?
Content-Length is mentioned in the Common Internet Message Headers memo as one of the non-standard message headers. It is used by some email providers such as Yahoo and AOL, and it contains a decimal number representing the number of bytes found in the payload of the message.
Let’s take a look at an example message:
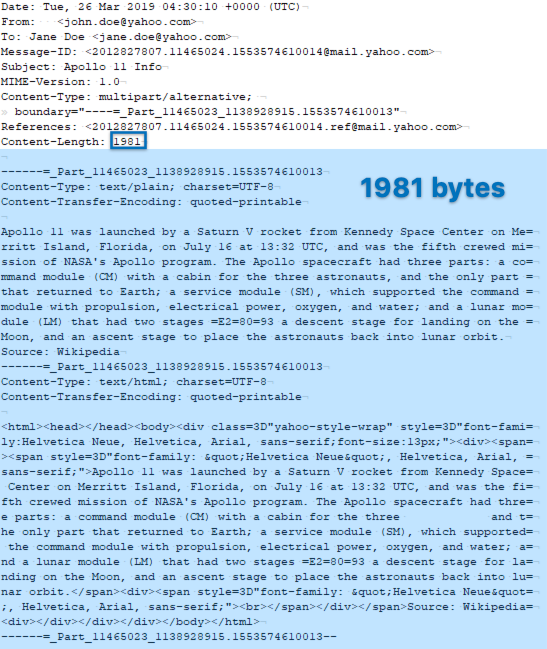
Figure 1 — Sample Email with Content-Length Header Field
The Content-Length header field for the above message is populated as 1981. If we count the number of characters in the message after the message header, including the newline character on the blank line following the Content-Length header field and the new line characters at the end of each subsequent line, we find that the number of characters in the message payload is in fact 1981.
TIP: You can count the characters very quickly by using a text editor. I use BBEdit on Mac and UltraEdit on PC, and they both count the characters automatically when you highlight the text. It is important that you count the line breaks as a single byte as in Unix (LF), not as two bytes as in Windows (CR/LF). If you are doing this on a Windows system, you can achieve this by setting up your text editor to use Unix-style line endings.
Here is a quick screen capture showing how we can count the characters:

Figure 2 — Calculating Payload Size
The sample message I used above was a short one to make illustration easier. This technique also works for much larger messages, including ones containing several attachments.
How Can We Use the Content-Length Field in Email Forensics?
It’s not hard to imagine how the Content-Length header field can be useful in a forensic examination. For instance, if we are looking at an authentic email acquired from Yahoo, we should expect the message payload to agree with the value found in the Content-Length field. A discrepancy might mean that the message body, the header, or both might have been manipulated.
In order to utilize this data point, the target email message should be preserved in its original form. For instance, if you logged into Yahoo webmail and used the “view raw message” menu item and saved the message as an EML, you could utilize the Content-Length value in your forensic exam. Similarly, acquiring the messages using Forensic Email Collector results in a hash match with the manual method above, and lends itself to a content-length comparison.
If you are not focused on a single message, but you are looking at a larger data set, you could automate things by writing a script to scan a folder full of MIME messages (e.g., FEC’s MIME output folder) and comparing their Content-Length values to their payload byte counts in bulk. You can then log the discrepancies and take a closer look at them as part of your email examination workflow.
Another use case can be when examining a fraudulent message that was created by repurposing an already existing, legitimate message. If the fraudulent message and the legitimate message have the same Content-Length header field value, and that value matches only the payload length of the legitimate message, this could be a valuable data point that can be used to show which message is the true copy.
What Not To Do
Every character counts when calculating the byte count of the message payload. If the message changes in any way, including text encoding and MIME boundary delimiters, the calculation would be thrown off.
You will find that if you acquire the messages and convert them to another format, the Content-Length value often no longer matches the payload length—even if you convert back to MIME format. For instance, acquiring the messages using Outlook, ingesting the resultant OST into your email investigation tool, and then going back to EML format, in my experience, does not work. This is one of the reasons why I recommend keeping the MIME format of the messages during forensic preservation. The amount of additional disk space is often negligible compared to the forensic value you get.
Conclusion
Not every message header contains the Content-Length field. But when available, Content-Length can be a very valuable data point during forensic email investigations. In order to make use of it, forensic examiners should make an effort to preserve emails in the format that is the closest to the original format of the email. In most cases, this is MIME format as defined by RFC 5322.
If your target message contains the Content-Length header field, don’t simply ignore it. Research how that field is populated for the service provider you are dealing with, and determine whether its contents are consistent with how the field would be populated for a legitimate message.
References:
RFC-5322: Internet Message Format — https://tools.ietf.org/html/rfc5322
RFC-2076: Common Internet Message Headers — https://tools.ietf.org/html/rfc2076